Mnożenie macierzy
-- Sebastian Pawlak, 2002.
Projekt ilustruje problematykę równoległego mnożenia macierzy.
Program operuje na pamięci przydzielanej dynamicznie.
Jeden z procesów (Master) wczytuje obie macierze do pamięci,
a następnie rozsyła odpowiednie fragmenty do pozostałych procesów.
Wyniki obliczeń są przesyłane do jednego
procesu, który zapisuje całościowy wynik do pliku.
Format plików z macierzami
Macierze będą przechowywane w dwóch osobnych plikach.
Ponieważ mnożenie będzie wykonywane dla bardzo
dużych macierzy toteż najrozsądniejszym formatem
plików będzie:
int liczbaWierszy; int liczbaKolumn; double macierz [liczbaWierszy * liczbaKolumn]; przy czym: sizeof(int) = 4, sizeof(double) = 8
Przykładowy program zapisujący macierz do pliku
Kod źródłowy pliku "tworzmacierz.c":
/*
* Program tworzy plik z macierza o zadanych
* wymiarach.
* Program pozwala tworzyc bardzo duze pliki.
*/
#include <stdio.h>
#include <fcntl.h>
#define PERMISSION 0666
#define PRZYROST 0.45
#define ROZMIAR_BUF 1000000
void err(char *komunikat)
{
printf("%s\n", komunikat);
exit(1);
}
int main(int argc, char **argv)
{
int plik;
int liczbaWierszy, liczbaKolumn;
int i, j, k;
double *buf;
if(argc != 4)
err("./tworzmacierz m n plikWynikowy\n"\
"gdzie: m - liczba wierszy macierzy,\n"\
" n - liczba kolumn macierzy.");
if((plik = creat(argv[3], PERMISSION)) == -1)
err("nie moge utworzyc pliku");
if(!(buf = (double *)malloc(ROZMIAR_BUF *
sizeof(double))))
err("nie moge przydzielic pamieci");
j = (liczbaWierszy = atoi(argv[1])) *
(liczbaKolumn = atoi(argv[2]));
write(plik, &liczbaWierszy, sizeof(int));
write(plik, &liczbaKolumn, sizeof(int));
k = 0;
while(k < j) {
for(i = 0; k + ROZMIAR_BUF > j ? i < j - k :
i < ROZMIAR_BUF; i++)
buf[i] = (double)(i + k) * PRZYROST;
write(plik, buf, i * sizeof(double));
k += i;
}
free(buf);
close(plik);
return 0;
}
Przykładowy program wczytujący macierz z pliku do pamięci przydzielanej dynamicznie
Kod źródłowy pliku "wczytajmacierz.c":
/*
* Program wczytuje macierz z pliku do
* pamieci.
*/
#include <stdio.h>
#include <fcntl.h>
void err(char *komunikat)
{
printf("%s\n", komunikat);
exit(1);
}
int main(int argc, char **argv)
{
int plik;
int liczbaWierszy, liczbaKolumn;
int i, j;
double *buf;
if(argc != 2)
err("./wczytajmacierz plikWejsciowy");
if((plik = open(argv[1], O_RDONLY, 0)) == -1)
err("nie moge otworzyc pliku z macierza");
read(plik, &liczbaWierszy, sizeof(int));
read(plik, &liczbaKolumn, sizeof(int));
j = liczbaWierszy * liczbaKolumn;
if(!(buf = (double *)malloc(j * sizeof(double))))
err("nie moge przydzielic pamieci");
read(plik, buf, j * sizeof(double));
close(plik);
/* wypisz macierz na ekran */
for(i = 0; i < j; i++) {
printf("%6g", buf[i]);
!((i + 1) % liczbaKolumn) ?
printf("\n") : printf(" ");
}
free(buf);
return 0;
}
Nie stanowi problemu wczytanie macierzy do tablicy dwuwymiarowej
(tablicy tablic) lub
tablicy wskaźników.
Jednak C nie gwarantuje spójności przydzielonego obszaru pamięci
dla poszczególnych wierszy, dlatego wczytywanie należy wykonać wiersz
po wierszu.
Metoda rozwiązania - opis metody sekwencyjnej
Program realizujący przedstawiony algorytm Matrix-Multiply
przedstawia się następująco:
Kod źródłowy pliku "sekwencyjna.c":
/*
* Sekwencyjne mnozenie macierzy.
*/
#include <stdio.h>
#include <fcntl.h>
void err(char *komunikat)
{
printf("%s\n", komunikat);
exit(1);
}
void wypiszMacierz(double *buf, int liczbaWierszy,
int liczbaKolumn)
{
int i, j = liczbaWierszy * liczbaKolumn;
for(i = 0; i < j; i++) {
printf("%6g", buf[i]);
!((i + 1) % liczbaKolumn) ?
printf("\n") : printf(" ");
}
}
int main(int argc, char **argv)
{
int plik;
int liczbaWierszyA, liczbaKolumnA,
liczbaWierszyB, liczbaKolumnB;
int i, j, k;
double *bufA, *bufB, *bufC;
if(argc != 3)
err("./sekwencyjna macierzA macierzB");
/* wczytywanie macierzy A */
if((plik = open(argv[1], O_RDONLY, 0)) == -1)
err("nie moge otworzyc pliku z macierza A");
read(plik, &liczbaWierszyA, sizeof(int));
read(plik, &liczbaKolumnA, sizeof(int));
j = liczbaWierszyA * liczbaKolumnA;
if(!(bufA = (double *)malloc(j * sizeof(double))))
err("nie moge przydzielic pamieci na bufA");
read(plik, bufA, j * sizeof(double));
close(plik);
printf("Macierz A\n");
wypiszMacierz(bufA, liczbaWierszyA,
liczbaKolumnA);
/* wczytywanie macierzy B */
if((plik = open(argv[2], O_RDONLY, 0)) == -1)
err("nie moge otworzyc pliku z macierza B");
read(plik, &liczbaWierszyB, sizeof(int));
read(plik, &liczbaKolumnB, sizeof(int));
j = liczbaWierszyB * liczbaKolumnB;
if(!(bufB = (double *)malloc(j * sizeof(double))))
err("nie moge przydzielic pamieci na bufB");
read(plik, bufB, j * sizeof(double));
close(plik);
printf("\nMacierz B\n");
wypiszMacierz(bufB, liczbaWierszyB,
liczbaKolumnB);
/* przydzielenie pamieci na macierz wynikowa C */
if(!(bufC = (double *)malloc(liczbaWierszyA *
liczbaKolumnB * sizeof(double))))
err("nie moge przydzielic pamieci na bufC");
/* mnozenie macierzy */
for(i = 0; i < liczbaWierszyA; i++)
for(j = 0; j < liczbaKolumnB; j++) {
bufC[j + i * liczbaKolumnB] = 0;
for(k = 0; k < liczbaKolumnA; k++)
bufC[j + i * liczbaKolumnB] +=
bufA[k + i * liczbaKolumnA] *
bufB[j + k * liczbaKolumnB];
}
printf("\nMacierz C\n");
wypiszMacierz(bufC, liczbaWierszyA,
liczbaKolumnB);
free(bufC);
free(bufB);
free(bufA);
return 0;
}
Przedstawiony program można nieco zoptymalizować.
Poniżej przedstawiłem najistotniejsze
fragmenty poprawionej wersji programu.
Kod źródłowy pliku "sekwencyjna2.c":
/*
* Sekwencyjne mnozenie macierzy.
* Wersja zoptymalizowana.
*/
...
int i_liczbaKolumnB = 0, i_liczbaKolumnA = 0,
k_liczbaKolumnB = 0;
...
/* mnozenie macierzy - zoptymalizowane */
for(i = 0; i < liczbaWierszyA; i++) {
for(j = 0; j < liczbaKolumnB; j++) {
bufC[i_liczbaKolumnB] = 0;
k_liczbaKolumnB = j;
for(k = 0; k < liczbaKolumnA; k++) {
bufC[i_liczbaKolumnB] +=
bufA[k + i_liczbaKolumnA] *
bufB[k_liczbaKolumnB];
k_liczbaKolumnB += liczbaKolumnB;
}
i_liczbaKolumnB++;
}
i_liczbaKolumnA += liczbaKolumnA;
}
...
Wersja zoptymalizowana jest szybsza o średnio 23%,
co ilustruje poniższa tablica.
rozmiar | czas | czas | przyśpie- macierzy | normalny | optymalny | szenie ------------+----------+-----------+---------- 500 x 500 | 25,48 | 20,59 | 23,74% ------------+----------+-----------+---------- 1000 x 1000 | 228,77 | 186,92 | 22,3% ------------+----------+-----------+---------- Porównanie czasów działania przedstawionych programów sekwencyjnych
Metoda rozwiązania - opis metody równoległej
Master wczytuje obie macierze do pamięci przydzielanej dynamicznie.
Następnie druga macierz rozsyłana jest w całości do pozostałych procesów.
Macierz pierwsza dzielona jest wierszami, a następnie rozsyłana.
W poszczególnych procesach następuje wymnażanie fragmentów macierzy.
Wyniki obliczeń przesyłane są do Mastera, który scala je
oraz zapisuje wynikową macierz do pliku.
Optymalna wersja programu rozsyła w całości macierz mniejszą - dzięki
temu zaoszczędzamy pamięć oraz czas potrzebny na przesłanie macierzy.
Wtedy większą macierz dzieli się kolumnami (jeśli w całości przesłaliśmy
macierz pierwszą) albo wierszami (jeśli w całości przesłaliśmy
macierz drugą).
Kod źródłowy pliku "rownolegla.c":
/*
* Zrownoleglone mnozenie macierzy.
* Master wczytuje 2 macierze do swojej pamieci.
* Nastepnie rozsyla jedna macierz do Slave`ow.
* Macierz druga dzielona jest na fragmenty i
* rozsylana do Slave`ow.
* Wyniki obliczen wracaja do Mastera.
* Pamiec przydzielana jest dynamicznie - wektor.
*
* Sebastian Pawlak, s1222.
*/
#include <stdio.h>
#include <fcntl.h>
#include "mpi.h"
#define MAX_LICZBA_PROCESOW 16
#define PERMISSION 0666
void err(char *komunikat)
{
printf("%s\n", komunikat);
MPI_Abort(MPI_COMM_WORLD, -1);
}
int main(int argc, char **argv)
{
int plik;
int liczbaWierszyA, liczbaKolumnA,
liczbaWierszyB, liczbaKolumnB;
int i, j, k, n;
double *bufA, *bufB, *bufC;
int i_liczbaKolumnB = 0, i_liczbaKolumnA = 0,
k_liczbaKolumnB = 0;
int rank, size;
double czasStart;
struct przedzial {
int nMin, nMax;
} przedzialyTab[MAX_LICZBA_PROCESOW] = { 0 };
int tag = 55;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(argc != 4)
err("./rownolegla macierzA macierzB wynik");
if(rank == 0) {
/* wczytywanie macierzy A */
if((plik = open(argv[1], O_RDONLY, 0)) == -1)
err("nie moge otworzyc pliku A");
read(plik, &liczbaWierszyA, sizeof(int));
read(plik, &liczbaKolumnA, sizeof(int));
j = liczbaWierszyA * liczbaKolumnA;
if(!(bufA = (double *)malloc(
j * sizeof(double))))
err("nie moge przydzielic pamieci na A");
read(plik, bufA, j * sizeof(double));
close(plik);
/* wczytywanie macierzy B */
if((plik = open(argv[2], O_RDONLY, 0)) == -1)
err("nie moge otworzyc pliku z B");
read(plik, &liczbaWierszyB, sizeof(int));
read(plik, &liczbaKolumnB, sizeof(int));
k = liczbaWierszyB * liczbaKolumnB;
if(!(bufB = (double *)malloc(
k * sizeof(double))))
err("nie moge przydzielic pamieci na B");
read(plik, bufB, k * sizeof(double));
close(plik);
/* przydzielenie pamieci na macierz C */
if(!(bufC = (double *)malloc(liczbaWierszyA *
liczbaKolumnB * sizeof(double))))
err("nie moge przydzielic pamieci na C");
/* Master przydziela fragmenty macierzy */
przedzialyTab[0].nMin = 0;
przedzialyTab[0].nMax =
dzielenie(liczbaWierszyA, size) - 1;
for(i = 1; i < size; i++) {
przedzialyTab[i].nMin =
przedzialyTab[i - 1].nMax + 1;
przedzialyTab[i].nMax =
dzielenie(liczbaWierszyA -
przedzialyTab[i - 1].nMax - 1, size -
i) + przedzialyTab[i - 1].nMax;
}
}
czasStart = MPI_Wtime(); /* pomiar czasu */
/* rozsylanie informacji o przedzialach do
* poszczegolnych procesow
*/
MPI_Scatter(przedzialyTab,
sizeof(struct przedzial), MPI_BYTE,
przedzialyTab,
sizeof(struct przedzial), MPI_BYTE,
0, MPI_COMM_WORLD);
MPI_Bcast(&liczbaWierszyB, 1, MPI_INT, 0,
MPI_COMM_WORLD);
MPI_Bcast(&liczbaKolumnB, 1, MPI_INT, 0,
MPI_COMM_WORLD);
/* rozsylanie macierzy B do procesow */
if(rank != 0 &&
!(bufB = (double *)malloc(liczbaWierszyB *
liczbaKolumnB * sizeof(double))))
err("nie moge przydzielic pamieci na B");
MPI_Bcast(bufB, liczbaWierszyB * liczbaKolumnB,
MPI_DOUBLE, 0, MPI_COMM_WORLD);
/* rozsylanie macierzy A we fragmentach */
MPI_Bcast(&liczbaKolumnA, 1, MPI_INT, 0,
MPI_COMM_WORLD);
if(rank == 0)
for(i = 1; i < size; i++)
MPI_Send(bufA + przedzialyTab[i].nMin *
liczbaWierszyA,
(przedzialyTab[i].nMax -
przedzialyTab[i].nMin + 1) *
liczbaKolumnA, MPI_DOUBLE, i,
tag, MPI_COMM_WORLD);
else {
i = (przedzialyTab[0].nMax -
przedzialyTab[0].nMin + 1) *
liczbaKolumnA;
if(!(bufA = (double *)malloc(i *
sizeof(double))))
err("nie moge przydzielic pamieci na A");
MPI_Recv(bufA, i, MPI_DOUBLE, 0, tag,
MPI_COMM_WORLD, &status);
}
if(rank != 0 &&
!(bufC = (double *)malloc(
(przedzialyTab[0].nMax -
przedzialyTab[0].nMin + 1) *
liczbaKolumnB * sizeof(double))))
err("nie moge przydzielic pamieci na C");
/* mnozenie macierzy */
n = przedzialyTab[0].nMax -
przedzialyTab[0].nMin + 1;
for(i = 0; i < n; i++) {
for(j = 0; j < liczbaKolumnB; j++) {
bufC[i_liczbaKolumnB] = 0;
k_liczbaKolumnB = j;
for(k = 0; k < liczbaKolumnA; k++) {
bufC[i_liczbaKolumnB] +=
bufA[k + i_liczbaKolumnA] *
bufB[k_liczbaKolumnB];
k_liczbaKolumnB += liczbaKolumnB;
}
i_liczbaKolumnB++;
}
i_liczbaKolumnA += liczbaKolumnA;
}
/* Master zbiera wyniki */
if(rank == 0)
for(i = 1; i < size; i++)
MPI_Recv(bufC + przedzialyTab[i].nMin *
liczbaKolumnB,
(przedzialyTab[i].nMax -
przedzialyTab[i].nMin + 1)
* liczbaKolumnB, MPI_DOUBLE, i,
tag, MPI_COMM_WORLD, &status);
else
MPI_Send(bufC, (przedzialyTab[0].nMax -
przedzialyTab[0].nMin + 1) *
liczbaKolumnB, MPI_DOUBLE, 0, tag,
MPI_COMM_WORLD);
if(rank == 0) {
printf("liczba procesow %d\n", size);
printf("czas wykonywania programu %g "\
"sekund\n", MPI_Wtime() - czasStart);
if((plik = creat(argv[3], PERMISSION)) == -1)
err("nie moge utworzyc pliku");
write(plik, &liczbaWierszyA, sizeof(int));
write(plik, &liczbaKolumnB, sizeof(int));
write(plik, bufC, liczbaWierszyA *
liczbaKolumnB * sizeof(double));
close(plik);
}
free(bufC);
free(bufB);
free(bufA);
MPI_Finalize();
return 0;
}
/*
* Funkcja zwraca, zaokraglony do liczby calkowitej,
* wynik dzielenia dwoch liczb. Gdy liczba
* po przecinku jest >= 0.5 to wynik zaokraglany
* jest w gore.
*/
int dzielenie(int dzielna, int dzielnik)
{
return (double)dzielna / dzielnik -
(double)(dzielna / dzielnik) >= 0.5
? dzielna / dzielnik + 1
: dzielna / dzielnik;
}
Problemy występujące w implementacji
W założeniach do programu przyjąłem, że proces Master wczytuje,
do swojej pamięci, macierze w całości,
a następnie rozsyła je (lub ich fragmenty) do pozostałych procesów.
Takie postępowanie znacznie ogranicza wielkości macierzy, które będą mnożone.
Należało zredukować ilość danych przesyłanych pomiędzy procesorami.
W tym celu należy wybrać mniejszą z macierzy i właśnie tę wysyłać
w całości - dzielić na fragmenty należy macierz większą.
Testy i rezultaty
Poniższa tablica obrazuje wyniki testów przeprowadzonych na ,,superkomputerze'' SR2201.
Obie mnożone macierze miały wymiary 1500 x 1500.
liczba procesów | czas [sekundy]
----------------+---------------
1 | 2473,3
2 | 1234,75
3 | 825,357
4 | 618,305
5 | 495,842
6 | 413,310
7 | 361,914
8 | 316,493
9 | 282,699
10 | 253,599
11 | 232,138
12 | 211,132
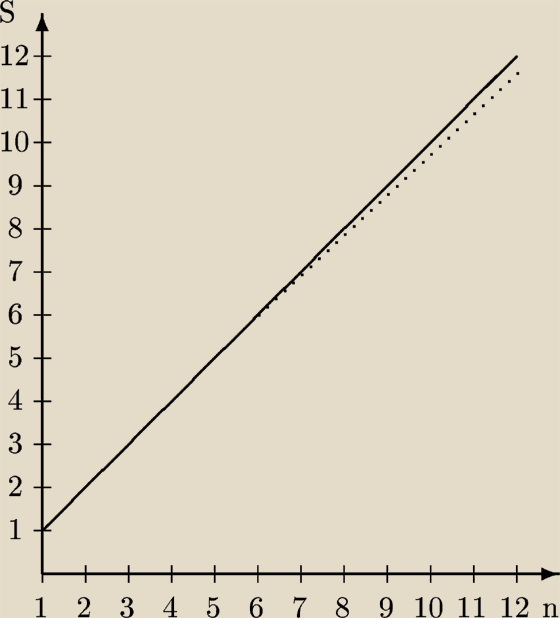
Speedup - przyśpieszenie; S - przyśpieszenie, n - liczba procesów; linia ciągła - przyśpieszenie idealne; linia przerywana - przyśpieszenie rzeczywiste
Sposób uruchamiania programów na partycji j12:
echo "/usr/local/mpi/bin/mpirun -np 12 -p j12 `pwd`/rownolegla
`pwd`/A `pwd`/B `pwd`/C" | qsub -N 12 -q j12